

转自雷锋字幕组双语文章原文: 推荐!最适合初学者的18个经典开源计算机视觉项目英语原文: 18 All-Time Classic Open Source Computer Vision Projects for Beginners翻译: 雷锋字幕组(小哲)开源计算机视觉项目是在深度学习领域中获得一席之地的绝佳路径开始学习这18个非常受欢迎的经典开源计算机视觉项目
计算机视觉的应用现在无处不在. 老实说,我已经不记得上次一整天没有遇到或者没有与至少一样计算机视觉使用样例进行交互时什么时候了(手机上的人脸识别)
但是有一件事情就是 一 想要学习计算机视觉的人倾向与陷入理论的概念, 这是所能采取的最糟糕的路. 为了真正的学习掌握计算机视觉, 我们需要将理论与实践相结合.
并且这就是开源计算机视觉项目存在的地方. 不需要花一分钱就可以练习计算机视觉技术——你可以坐在现在的位置上完成这些工作.

所以在这篇文章中, 我结合并创建了一个基于计算机视觉各种应用的开源计算机视觉项目列表.有很多事情要做,这是一个相当全面的清单,所以让我们深入研究!
如果你是一个完全的计算机视觉和深度学习的新手并且更想要通过视频学习, 请参考下边:使用深度学习2.0 的计算机视觉图像分类人脸识别使用GAN的自然风格转换场景文字检测使用DETR的目标检测语义分割自动驾驶的道路交通线检测图像标注人类姿势估计通过面部表情的情感识别
图像分类是计算机视觉领域的基础任务, 目标是通过给每张图片分配一个标签来区分图像.对人类来说理解区分我们看到的图像很容易. 单是对于机器来说时非常不同的. 对于机器来说区分大象和汽车都是一件繁重的任务.
下边是几个最突出的图像分类开源项目:Cifar10
CIFAR-10是一个在训练机器学习和计算机视觉算法常用的数据集,它是机器学习最受欢迎的数据集. 包含了60000张图像, 分为10类, 每张图像的的尺寸为32x32. 类别有飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车.ImageNet
ImageNet数据集是一个为计算机视觉研究的巨大图像数据集, 这个数据集中有多于140万张图像被手供标注, 并且这些标注说明了图像中含有那些物体.并且有多余1万张图像标注了物品的边界框. ImageNet包含了多余20000类的物品.
作为初学者,你可以使用keras或者pytorch从头开始学习神经网络, 为了能够得到更好的效果提升学习的层次, 我建议使用迁移学习预训练模型,例如CGG-16, Resnet-50,GoogleNet等等.

top4的图像分类的python代码
建议通读下边的文章更好的理解图像分类:使用深度神经网络进行ImageNet的图像分类卷积层数加深(VGG)图像识别的深度残差网络(ResNet) 人脸识别的开源计算机视觉代码
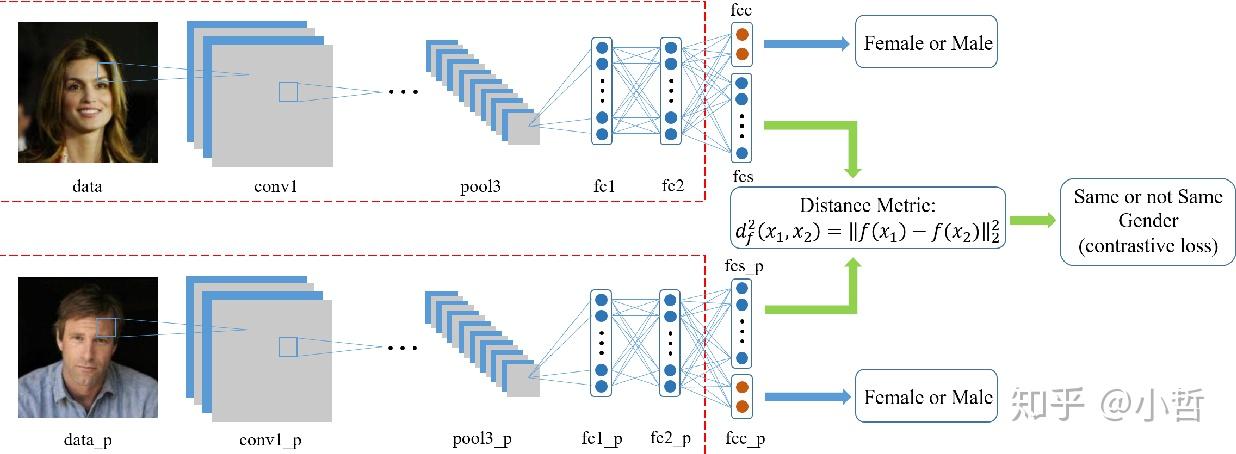
人脸识别是计算机视觉最广泛的应用.人脸识别被应用在安全, 监控或者解锁手机. 这是一个在预先存在的数据集中在图像或者视频中确认你的人脸. 我们可以使用深度学习的方法来学习这些人脸的特征并且识别他们.
这是一个多个步骤的过程,这个过程由以下的步骤构成:人脸检测: 这用来定位一个或者多个在图像或者视频中的人脸人脸对齐: 对齐是用来规范化人脸在集合上与数据集一致特征提取: 后来,提取特征并且用在识别任务中.特征识别: 与数据库中的特征相匹配
下面的开放源数据集将为您提供良好的人脸识别机会:MegaFace
MegaFace是一个大规模的公共人脸识别训练数据集,它是商业人脸识别问题最重要的基准之一.它包括4753320个人脸,672057个身份
Labeled faces in wild home(LFW)是一个人脸照片数据库,旨在研究无约束人脸识别问题.它有13233张5749人的图片,是从网上发现和收集的.另外,1680名照片中的人在数据集中有两张或两张以上不同的照片.
此外, 为了更好的利用这些项目, 你可以使用像FaceNet这样的预训练模型.
Facenet是一种深度学习模型,它为人脸识别、验证和聚类任务提供了统一的嵌入.网络将每个人脸都映射在一个欧几里德网络中,每个图像之间的距离是相似的.
资源
也可以使用keras或者pytorch的预训练模型来构建自己的人脸识别系统.
还有一些更先进的人脸识别模型可供使用.Deepface是由Facebook的研究人员开发的基于CNN的Deep网络.这是在人脸识别任务中使用深度学习的一个重要里程碑.
为了更好地了解近30年来人脸识别技术的发展,我建议您阅读一篇有趣的论文,题目是:Deep Face Recognition: A Survey 开源的计算机视觉项目 一 使用GAN进行自然风格转换
自然风格转换是一种使用一张图像的风格重建另一张图像的内容的计算机视觉技术.这是生成对抗网络(GAN)的应用, 这儿,我们输入了两张图像, 一张内容图像,另一张时风格参考图像, 然后将二者混合在一起以至于输出图像看起来像使用风格参考图像绘制出来的油画.
这是通过优化输出图像与内容图像匹配的内容统计和样式参考图像的样式统计来实现的. 
资源
下边是一些用来练习非常令人惊叹的数据集:COCO数据集
COCO是一个大规模的对象检测、分割和标注的数据集.数据集中的图像是从日常场景中捕获的日常对象.此外,它提供了多对象标记、分割掩码标注、图像标注和关键点检测,共有81个类别,使其成为一个非常通用和多用途的数据集.ImageNet 上边已经提到过 一 ImageNet非常灵活多用
如果你还不知道如何应用风格转换模型,这儿是一个tensorflow的教程可以帮助你, 而且, 如果你像更加升入了解这个技术我建议你阅读接下来的论文.艺术风格的学术表达使用循环一致对抗网络的无需配对的图像到图像的转换使用卷积神经网络进行图像分割转换
在任何给定的场景中检测给定的场景是另外的一个非常有趣的问题. 场景文字就是出现在户外拍摄的图像中出现的字符. 例如, 道路上的车牌号, 道路上的公告牌等等.
场景图像中的文字在形状, 字体, 颜色和位置上都是变化的.由于光照和聚焦的不均匀性,使得场景文本识别的复杂度进一步增加.
大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
下边这些流行的数据集将会丰富你分析场景文字检测的技能:SVHN
街景门牌号码(SVHN)数据集是其中最受欢迎的开源数据集之一.它已用于Google创建的神经网络中,以读取门牌号并将其与地理位置匹配.这是一个很好的基准数据集,可用于练习, 学习和训练可准确识别街道编号的模型.此数据集包含从Google街景视图中获取的超过60万张带标签的真实房门图像.SceneText数据集
场景文本数据集包含在不同环境中捕获的3000张图像,包括在不同光照条件下的室外和室内场景.图像是通过使用高分辨率数码相机或低分辨率移动电话相机捕获的.此外,所有图像均已调整为640×480.
此外,场景文本检测是一个两步过程,包括图像中的文本检测和文本识别.对于文本检测,我发现了最先进的深度学习方法EAST(高效准确场景文本检测器).它可以找到水平和旋转边界框.您可以将其与任何文本识别方法结合使用.
这是有关场景文本检测的其他一些有趣的论文:使用链接主义文本提议网络检测自然图像中的文本COCO-Text:用于自然图像中文本检测和识别的数据集和基准
目标检测是通过边界框以及图像上的适当标签预测图像中存在的每个感兴趣对象的任务.
几个月前,Facebook开源了其对象检测框架DEtection TRansformer(DETR).DETR是针对目标检测问题的高效创新解决方案.通过将对象检测视为直接设置的预测问题,它简化了训练管道.此外,它采用基于变压器的编码器-解码器架构.

要了解有关DERT的更多信息,请参见论文和Colab notebook.
通过处理以下用于对象检测的开源数据集来使您的资料多样化:open Images
Open Image是约900万张图像的数据集,其中标注了图像级标签,对象边界框,对象分割掩码,视觉关系和本地化描述.数据集分为训练集(9,011,219张图像),验证集(41,620张图像)和测试集(125,436张图像).MSCOCO
MS-COCO是广泛用于目标检测问题的大规模数据集.它由33万张图像组成,其中包含80个对象类别,每个图像有5个标注,并有25万关键点.
您可以阅读以下资源以了解有关对象检测的更多信息:基本对象检测算法的分步介绍使用流行的YOLO框架进行对象检测的实用指南Facebook AI推出检测转换器(DETR)–一种基于transformer的对象检测方法!
当我们谈论计算机视觉技术中对场景的完全理解时,语义分割就出现了.任务是将图像中的所有像素分类为相关对象类别.大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!

以下是实践该主题的开源数据集的列表:CamVid
该数据库是开源的第一个按语义分割的数据集之一.这通常用于(实时)语义分割研究中.数据集包含:367训练对101个验证对 233个测试对 Cityscapes
该数据集是原始城市景观的经过处理的子样本.数据集具有原始视频的静止图像,并且语义分割标签显示在原始图像旁边的图像中.这是用于语义分割任务的最佳数据集之一.它具有2975个训练图像文件和500个验证图像文件,每个图像文件均为256×512像素
要进一步了解语义分段,我将推荐以下文章:语义分割:Google Pixel相机背后的深度学习技术简介!
以下是一些可用于语义分割的代码的论文:带有空洞可分离卷积的编码器-解码器用于语义图像分割DeepLab:使用深度卷积网络,空洞卷积和完全连接的CRF的语义图像分割
一个自主轿车是能够感知周围环境,并无需人类干预就能操作的交通工具.他们根据适合车辆不同部分的各种传感器创建并维护周围环境的地图.
这些车辆具有监视附近车辆位置的雷达传感器.摄像机检测交通信号灯,读取路标,跟踪其他车辆以及激光雷达(光检测和测距)传感器从汽车周围反射光脉冲以测量距离,检测道路边缘并识别车道标记
车道检测是这些车辆的重要组成部分.在公路运输中,车道是行车道的一部分,被指定用于单行车辆来控制和引导驾驶员并减少交通冲突.

在您的数据科学家的简历中添加一个令人兴奋的项目.以下是一些可用于实验的数据集-TUsimple
该数据集是Tusimple车道检测挑战赛的一部分.它包含3626个视频片段,每个片段1秒.这些视频剪辑中的每一个都包含20帧,并带有带注释的最后一帧.它包含训练和测试数据集,其中包含3626个视频片段,训练数据集中的3626个带注释的帧和2782个用于测试的视频片段.
如果您正在寻找一些开发项目的教程,请查看下面的文章-使用OpenCV进行实时车道检测的动手教程(无人驾驶汽车项目!)
您是否曾经希望过一些可以为社交媒体图像添加标注的技术,因为您和您的朋友都无法提出超酷的标注?用于图像标注的深度学习助您一臂之力.
图像标注是为图像生成文本描述的过程.它是计算机视觉和自然语言处理(NLP)的组合任务.
计算机视觉方法有助于理解并从输入图像中提取特征.此外,NLP以正确的单词顺序将图像转换为文本描述.
以下是一些有用的数据集,可帮助您使用图像标注:COCO Caption
COCO是大规模的对象检测,分割和标注数据集.它由330万张图像(标有> 200K)组成,具有150万个对象实例和80个对象类别,每个图像有5个标题.Ficker 8K 数据集
它是一个图像标注语料库,由158,915个众包字幕组成,描述了31,783张图像.这是Flickr 8k数据集的扩展 .新的图像和标注集中于进行日常活动和事件的人们.
如果您正在寻找项目的实施,我建议您看下面的文章:在PyTorch中使用深度学习(CNN和LSTM)进行自动图像字幕大佬们都在玩{精选官网网址: www.vip333.Co }值得信任的品牌平台!
另外,我建议您阅读有关图像标注的著名论文.
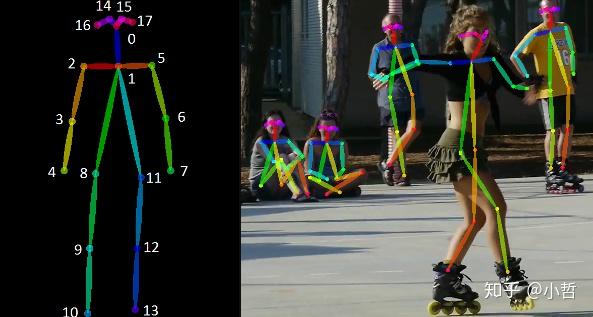
人体姿势估计是计算机视觉的有趣应用.您一定已经听说过Posenet,它是用于人体姿势估计的开源模型.简而言之,姿势估计是一种计算机视觉技术,可以推断图像/视频中存在的人或物体的姿势.
在讨论姿势估计的工作之前,让我们首先了解“人体姿势骨架”.它是定义一个人的姿势的一组坐标.一对坐标是肢体.此外,通过识别,定位和跟踪图像或视频中人类姿势骨架的关键点来执行姿势估计.
资源
如果要开发姿势估计模型,以下是一些数据集:MPII
MPII Human Pose数据集是评估关节式姿势估计的最新基准.该数据集包含约25K图像,其中包含超过4 万名带注释的人体关节的人.总体而言,数据集涵盖410种人类活动,每个图像都有一个活动标签.HUMANEVA
HumanEva-I数据集包含与3D人体姿势同步的7个校准视频序列.该数据库包含执行6个常见动作(例如,步行,慢跑,打手势等)的4个主题,这些动作被分为训练,验证和测试集.
我发现Google的DeepPose是一篇使用深度学习模型进行姿势估计非常有趣的研究论文.此外,您可以访问有关姿势估计的多个研究论文,以更好地理解它.
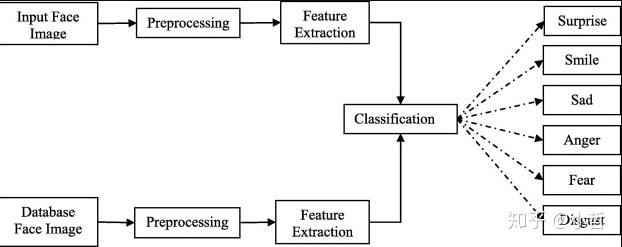
面部表情在非语言交流以及识别人的过程中起着至关重要的作用.它们对于识别人的情绪非常重要.因此,关于面部表情的信息通常用于情绪识别的自动系统中.
情绪识别是一项具有挑战性的任务,因为情绪可能会因环境,外观,文化和面部反应而异,从而导致数据不明确.
面部表情识别系统是一个多阶段过程,包括面部图像处理,特征提取和分类.
资源
以下是您可以用来练习的数据集:Real-world Affective Faces Database
真实世界的情感面孔数据库(RAF-DB)是一个大规模的面部表情数据库,包含约3万张多种多样的面部图像.它由29672个真实世界的图像和每个图像的7维表情分布矢量组成,
您可以阅读这些资源,以进一步了解您的内容-用于视频中的面部表情识别框架注意力网络姿势和遮挡鲁棒面部表情识别的区域注意网络
总而言之,在本文中,我们讨论了可以作为初学者实现的10个有趣的计算机视觉项目.这不是一个详尽的清单.因此,如果您觉得我们错过了什么,请随时在下面的评论中添加!
另外,在这里,我列出了一些有用的简历资源,以帮助您探索深度学习和计算机视觉世界:这是您在2020年掌握计算机视觉的学习途径使用深度学习2.0课程的计算机视觉认证项目:初学者的计算机视觉神经网络入门 (免费)从零开始的卷积神经网络(CNN)(免费)
我们在课程和自我练习中学习的数据科学与我们在行业中工作的数据科学有很多差异.我建议您参加这些非常清晰宝贵的免费课程,以了解有关分析,机器学习和人工智能的所有信息:机器学习/人工智能免费课程的简介 |移动app机器学习人工智能商业领导者移动APP简介商业分析免费课程的简介|移动app
我希望你能够觉得这次的讨论对您有意义, 现在轮到你开始自己应用计算机视觉了.


文章声明:以上内容(如有图片或视频在内)除非注明,否则均为原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://567256.com/post/520.html



